Essay
Generative Models for Video Prediction
Legacy presentation notes on GANs, VAEs, and autoregressive models for video prediction.
Introduce three generative models from the view of video prediction.
Why generative models should be applied in video prediction?
There are uncertainties in video prediction.

Discriminative models and Generative models
Discriminative Models Models are fed with , and supposed to produce correct with high probability.
Generative Models or
Models are supposed to model real data or distributions.
鈥淲hat I cannot create, I do not understand.鈥?/p> 鈥擱ichard Feynman
-
Generative Adversarial Network
-
Variable Autoencoder
-
PixelRNN / PixelCNN (Autoregressive Network)
Papers:
- Carl Vondrick, Hamed Pirsiavash, Antonio Torralba. “Generating videos with scene dynamics”, in NIPS 2016.
- Jacob Walker, Carl Doersch, Abhinav Gupta, Martial Hebert. “An Uncertain Future: Forecasting from Static Images using Variational Autoencoders”, in ECCV 2016.
- Nal Kalchbrenner, Aaron van den Oord, Karen Simonyan, Ivo Danihelka, Oriol Vinyals, Alex Graves, Koray Kavukcuoglu. “Video Pixel Networks”, Arxiv, 2016.
GAN (conceptual)
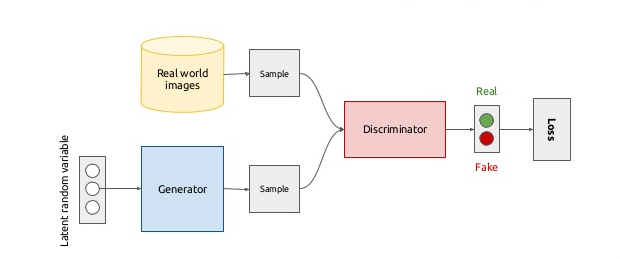 A typical gan model consists of generator and discriminator.
A typical gan model consists of generator and discriminator.
Generator part of VideoGAN.
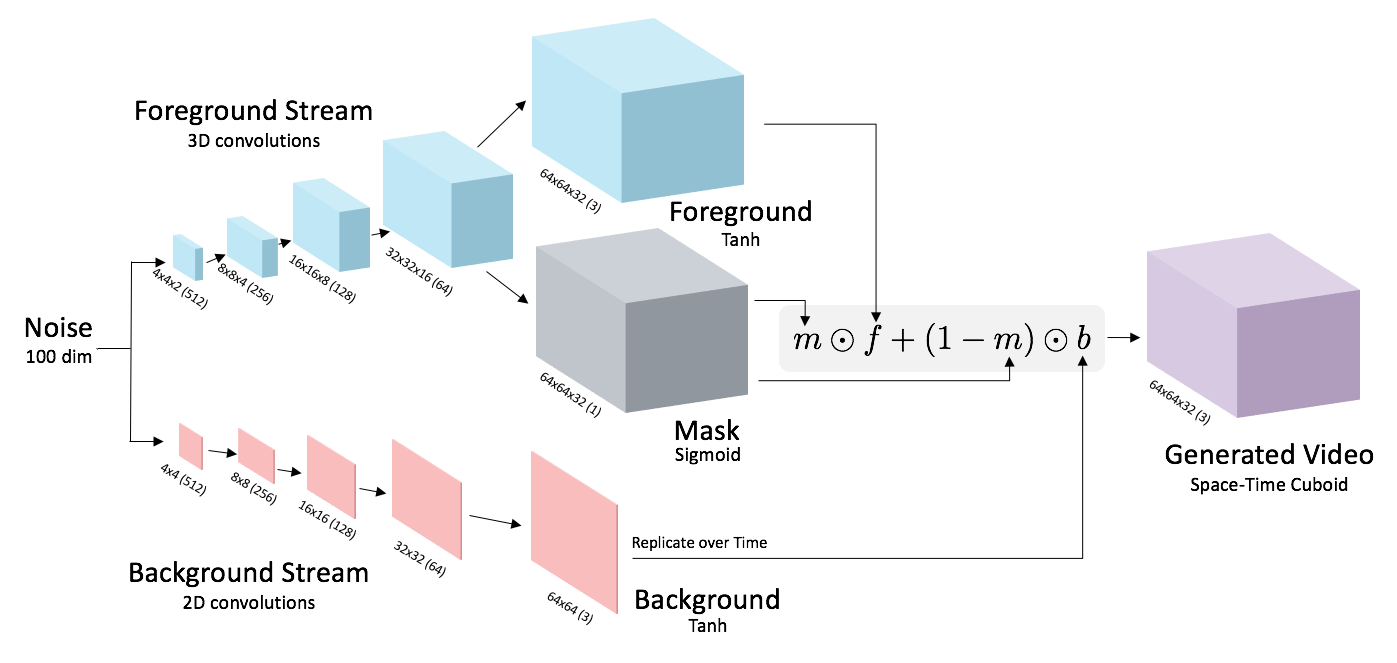 This generator can produce 32 frames at a time. Efficient!
This generator can produce 32 frames at a time. Efficient!
Selected generated clips
| Beach |  |
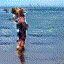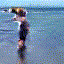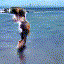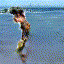 |
 |
 |
| golf | 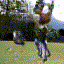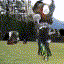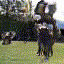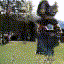 |
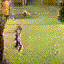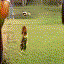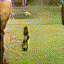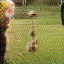 |
 |
 |
| train |  |
 |
 |
 |
| baby |  |
 |
 |
 |
Pros:
- Beautiful, state-of-the-art samples!
Cons:
- Trickier / more unstable to train.
- Can鈥檛 solve inference queries such as p(x), p(z|x).
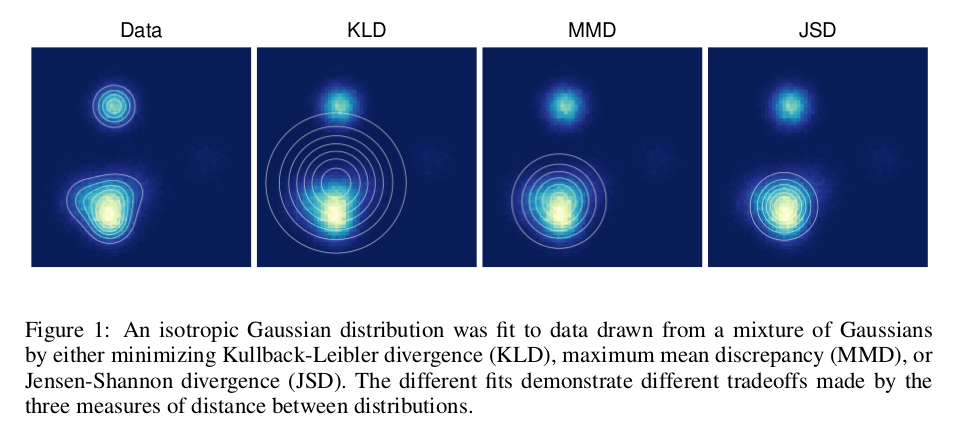
GAN belongs to the last one (JSD), while VAE and PixelRNN (PixelCNN) related to the second one (KLD).
Lucas Theis, A盲ron van den Oord, Matthias Bethge. “A note on the evaluation of generative models”, in ICLR 2016.
Variable Autoencoders
| Autoencoder | Encoder of VAE (inference) |
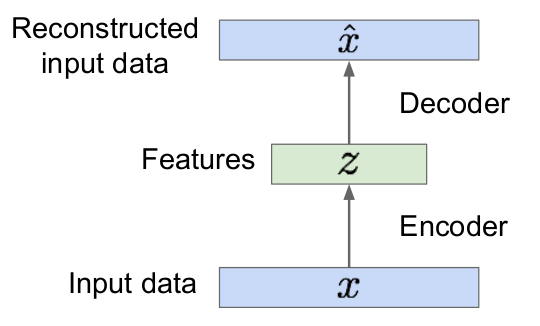 |
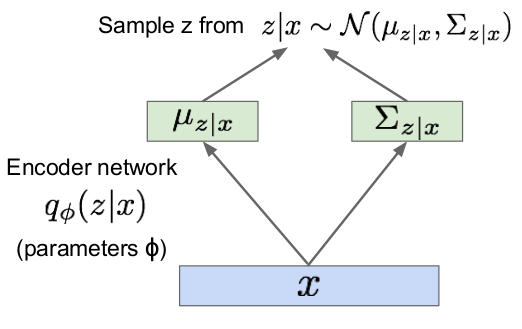 |
Diederik P Kingma, Max Welling. “Auto-Encoding Variational Bayes”, in ICLR 2014.
Maximize lower bound
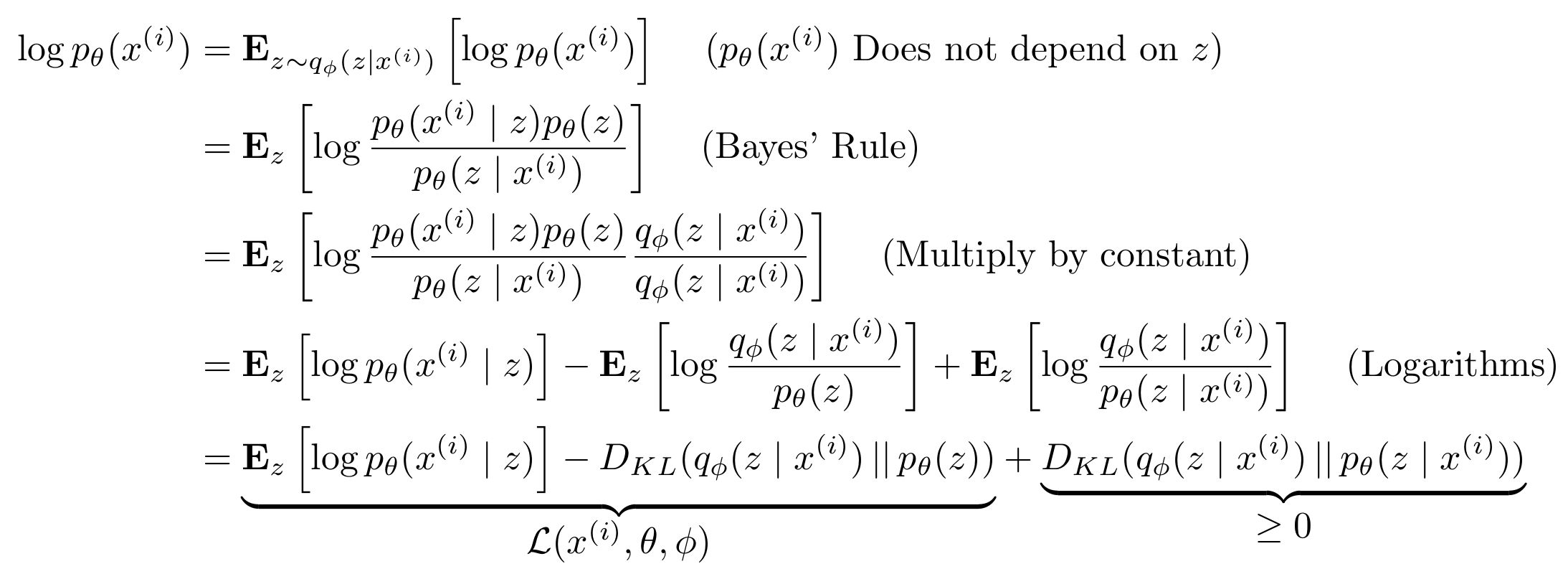
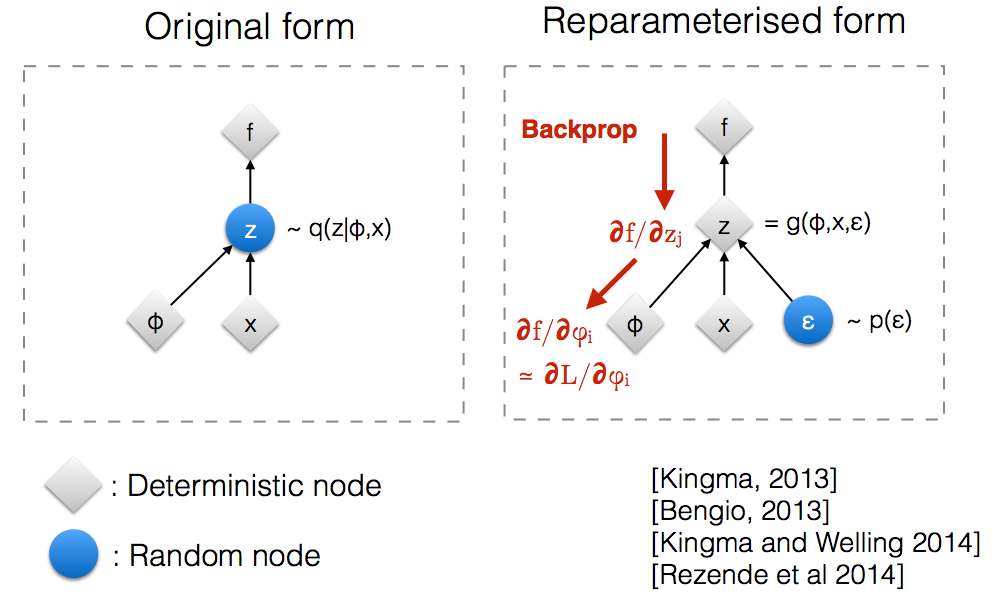
Reparameterization tricks
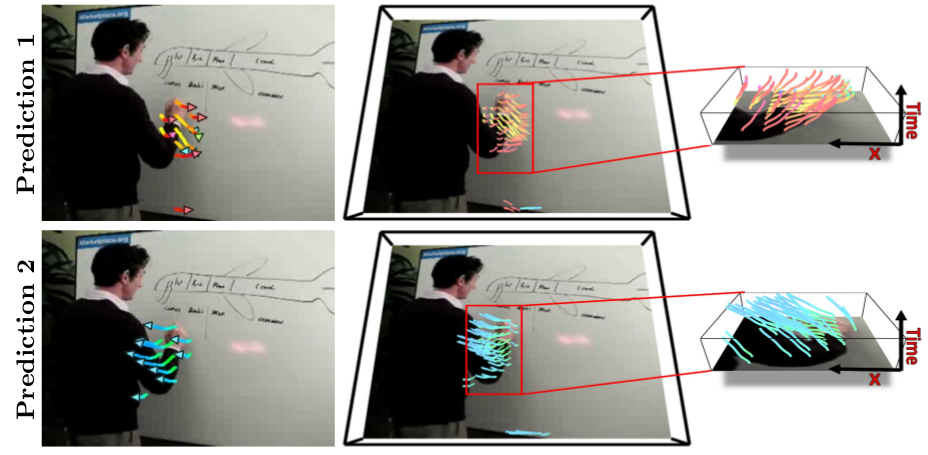
Predict dense trajectory
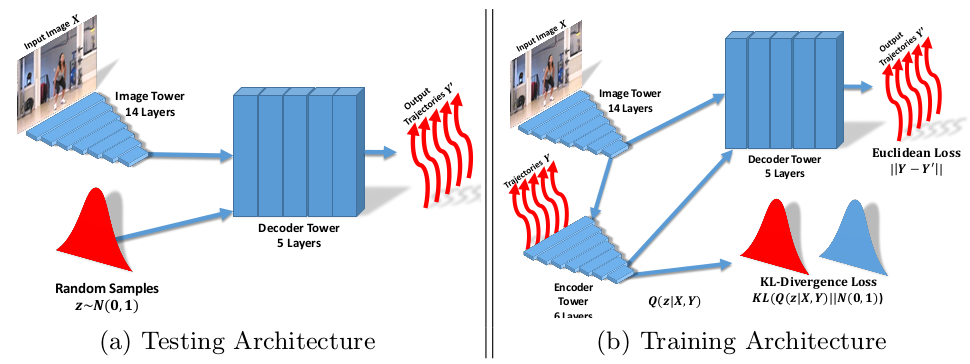 Jacob Walker, Carl Doersch, Abhinav Gupta, Martial Hebert. “An Uncertain Future: Forecasting from Static Images using Variational Autoencoders”, in ECCV 2016.
Jacob Walker, Carl Doersch, Abhinav Gupta, Martial Hebert. “An Uncertain Future: Forecasting from Static Images using Variational Autoencoders”, in ECCV 2016.
Results
Pros:
- Principled approach to generative models.
- Allows inference of , can be useful feature representation for other tasks.
Cons:
- Maximizes lower bound of likelihood: okay, but not as good evaluation as PixelRNN/PixelCNN.
- Samples blurrier and lower quality compared to state-of-the-art (GANs).
Negative log-likelihood for generative models on CIFAR-10 expressed as bits per sub-pixel.
![]()
Tim Salimans, Andrej Karpathy, Xi Chen, Diederik P. Kingma. “PIXELCNN++: improving the pixelcnn with discretized logistic mixture likelihood and other modifications”, ICLR 2017.
PixelRNN / PixelCNN
Basic formula:
Model every pixel iteratively with RNN.
Results in nats/frame on the Moving MNIST dataset.
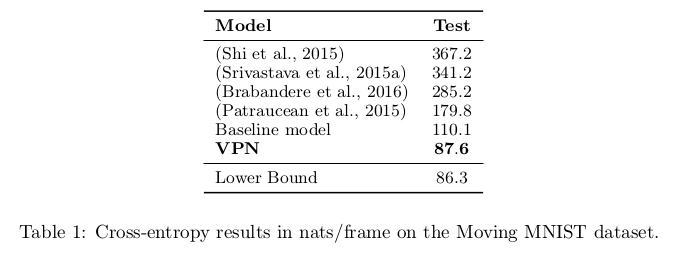 Nal Kalchbrenner, Aaron van den Oord, Karen Simonyan, Ivo Danihelka, Oriol Vinyals, Alex Graves, Koray Kavukcuoglu. “Video Pixel Networks”, Arxiv, 2016.
Nal Kalchbrenner, Aaron van den Oord, Karen Simonyan, Ivo Danihelka, Oriol Vinyals, Alex Graves, Koray Kavukcuoglu. “Video Pixel Networks”, Arxiv, 2016.
Pros:
- Can explicitly compute likelihood p(x).
- Explicit likelihood of training data gives good evaluation metric.
- Good samples.
Con:
- Sequential generation => slow.